Geek alert: This blog post is highly technical and assumes a certain level of Oscript development skills.
In my last blog, I discussed improvements made to the Distributed Agents framework in Update 201506. As a result of that post, John Simon asked if the improvements extended to capturing the results of child tasks on the Reduce() function. At the time, my research was inconclusive. Today I did a little experiment on two CS10.0 releases, one at U201503 and the other at U201506. The upshot is both behaved identically, so if the behaviour I’m citing is an improvement, it was introduced as early as U201503 (anyone from OpenText DEV care to comment?).
In a nutshell, it is possible to get results to bubble up from child task to master task. This happens in the Reduce() function. Unfortunately, any aggregated results don’t seem to make it to the Finalize task which is where most developers would like to get aggregated data about the results of the tasks that were executed.
So what aggregation *can* be done?
The Reduce() function gets data from two main locations, the list of assoc’s passed in as its one argument, and the .fTaskData feature on the Task object (i.e. your instance of your JobChain orphan). Tragically, .fTaskData means something completely different depending on what function you are in. i.e. within Split(), it’s the original assoc you passed in with your call to $DistributedAgent.MapReducePkg.Map(), but something else in Map(), Reduce(), and Finalize(). I summarize below:
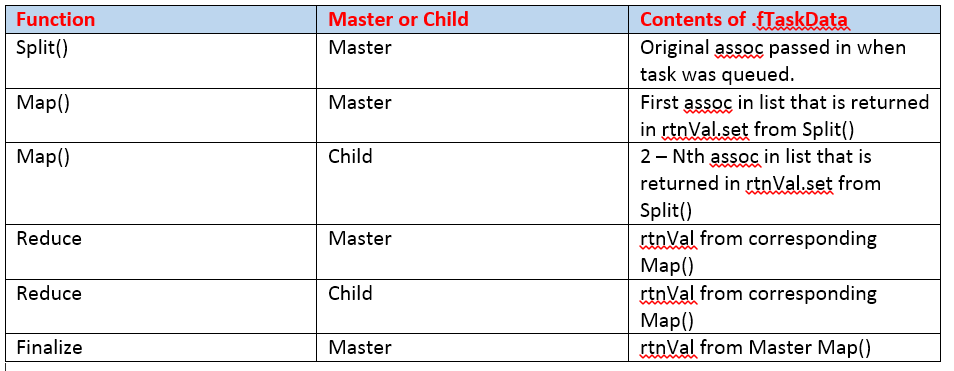
Yeah, it’s a bit messed up, and no wonder Oscript developers are often confused about what data they are getting when they are in different functions of the JobChain task object. Before I proceed with how to get child data to bubble up, let’s look at the sequence of events when a JobChain is kicked off. The sequence of events is:
- Master task executes Split() function, creates a set of Assoc’s for each portion of the job. This list of chunk task data’s is returned in the Split Function’s “set” feature (i.e. rtnVal.set).
- Master task executes Map() function for the first task data in the set from above (yeah, kind of weird)
- Child tasks are assigned for each other taskData in the set from above. That means if your split function only split into one chunk, everything gets executed in the Master task.
- Each Child task executes their Map() function. Any data you want to go to Reduce should go into retVal.Data for Map’s return
- Master task executes Reduce() and complains that child tasks outstanding (this sometimes creates an endless loop in builder, but it works fine when the server is running).
- Each child executes Reduce().
- Master task re-executes Reduce() and now succeeds
- Master task executes Finalize().
- And that’s the flow of execution.
Now, back to the question of how we aggregate data in the Reduce() function. As you see from above, the Master Reduce() tries to execute first (it containing the first taskData generated in Splot()). It exits out because child tasks are executing. The details of how master and child tasks map to one another is always subject to change. For our purposes we don’t need to know. In each child task’s running of Reduce(), the key thing is that at the end of the task, any details you want to get to the Master Reduce() go into rtnVal.childStatus. So let’s assume a Map() function like the following which returns an object count and a skipped count (i.e # of objects processed and skipped) in a data assoc:
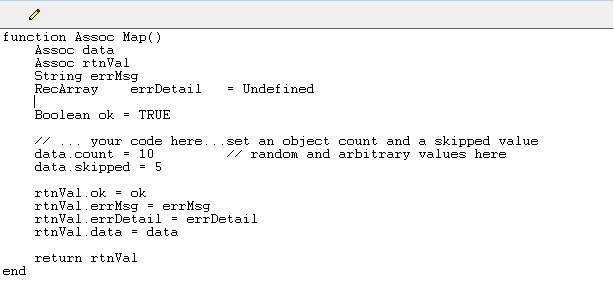
The Reduce() function will get an .fTaskData that is the rtnVal from the function above. You can then write the values of that data to Reduce’s rtnVal.childStatus assoc, i.e.
childStatus.data = .fTaskData.data rtnVal.childStatus = childStatus
When the master task executes Reduce(), it gets a list of all the childStatus Assoc’s from all the child tasks. If you loop through them, you would get the results of each Map task. These results along with the results stored in .fTaskData gives you all your task results in one location.
There is of course one small problem. Both a child task and a master task for which no child tasks executed will appear identical – both will have an empty list for the childResults argument.
There is a cheap trick to solve this. We can take advantage of the fact that in a Job Chain, when our split function splits the job up into smaller pieces, the Master task always takes the first item in the list – even if its a list of 1. If we were to assign a row count to each child taskData that indicates the row, and we returned that in our Map() function in the results, when we’re in Reduce() we would always know whether the task is a master with no children or a child by the rowcount. In Split() you’d do something like this:
RecArray rows = ...some SQL to get back our distributed results Record row Integer rowCount = 0 for row in rows Assoc chunkData = Assoc.Copy(.fTaskData) ...set whatever else you need to on chunkData chunkData.RowNumber = rowCount rowCount += 1 end
In the Map() function, you would add a line like
data.rowNumber = .fTaskData.RowNumber
Now your Reduce function would look something like:
/**
* This method will reduce the task results.
*
* @param {List} childResults Results from execution of child tasks
*
* @return {Assoc}
* @returnFeature {Boolean} ok FALSE if an error occurred, TRUE otherwise
* @returnFeature {String} errMsg Error message, if an error occurred
* @returnFeature {Assoc} childStatus ok/errMsg Assoc aggregating status of child results
* @returnFeature {Integer} childStatus.count Number of facets/columns indexed
* @returnFeature {RecArray} errDetail Detailed information about errors
*
**/
function Assoc Reduce(\
List childResults )
Assoc result
Assoc taskData = .fTaskData
Assoc data = taskData.data
// Assuming we set this up in Split(), RowNumber() will always be 0 for the
// master task
Boolean isMaster = IsDefined( data.RowNumber) && data.RowNumber == 0 ? TRUE : FALSE
// Get the results of the first task which was executed as the master
Integer count = data.count
Integer skipped = data.skipped
// Aggregate the rest of the results
if IsDefined( childResults )
for result in childResults
// Assume our child counts are in data
if IsDefined( result.data )
count += result.data.count
skipped += result.data.skipped
end
end
end
if isMaster
// do something with aggregated count/skipped integers
else
childStatus.data = data // For the child task, push this
end
rtnVal.ok = ok
rtnVal.errMsg = errMsg
rtnVal.errDetail = errDetail
rtnVal.childStatus = childStatus
return rtnVal
end
Using the above Reduce() function, we know which instance of Reduce() is our master, and we received an aggregated count from the Map(). Any other information could be passed such as error information from the child task. It is unfortunate that this information doesn’t bubble up to Finalize(), and perhaps that is what OpenText is still working on.
If you’ve read this far, you must be a veteran Oscripter 🙂 Comments are welcome, even to tell me I have something completely wrong.